
If you seek empirical economic studies that can be replicated, try my Shiny-based search app:
https://ejd.econ.mathematik.uni-ulm.de
The last couple of days, I was quite excited to explore the fantastic OpenAI API. First, I wrote mygpt, a package for customizable Chat-GPT addins in RStudio. Then I used using OpenAI’s text embeddings to improve my search app. You can now press a button with symbol ≈ next to an article to find similar articles:
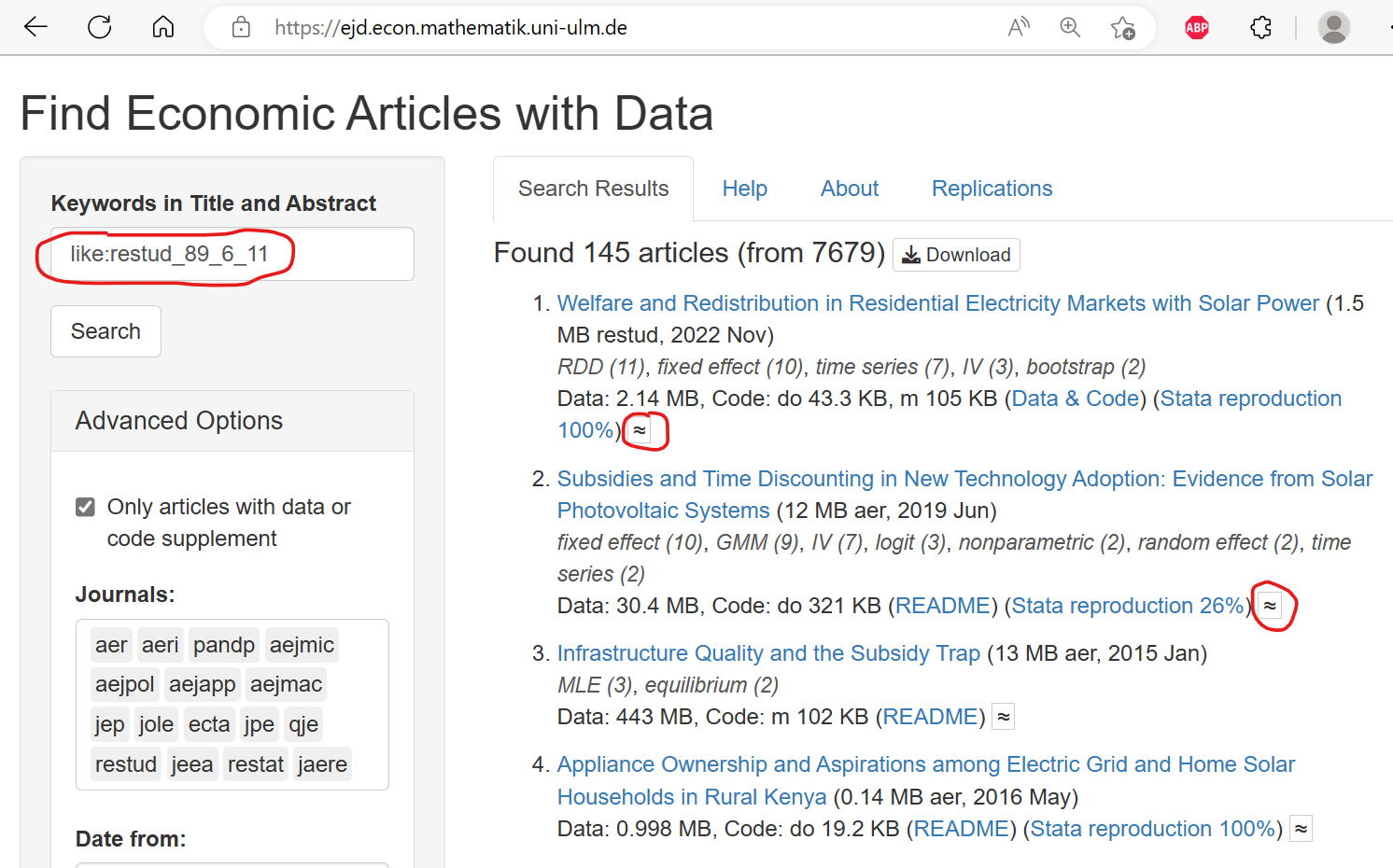
To implement this feature, I first used the newest OpenAI text embedding model “text-embedding-ada-002” to generate text embeddings for 8000+ abstracts. An embedding of an abstract is a vector of 1536 real numbers that represents information about its content. The API can be easily used from R and there are also R packages that wrap the OpenAI API, like rgpt3 or, partly, gpt4r.
Although the OpenAI API costs money after a free trial, it seems quite affordable. Generating embeddings for my 8000+ abstracts costs just about 0.50 USD.
With embeddings for each abstract, one can compute the similarity of two abstracts by computing the cosine similarity (which is quite similar to a correlation). As embeddings are nicely normalized, one can actually compute all similarities at once using a simple matrix product.
After the similarities were computed, I stored for each abstract the 200 closest abstracts from other articles. The resulting file is not very small and could weigh down the app if always loaded on start-up. To maintain performance, I store the results using the great fst package. It allows loading selective rows once a user presses the button to find similar articles.
Overall, I think that OpenAI’s embeddings do a quite good job of finding similar articles. But just try out yourself!
Looking ahead, I am excited to experiment with OpenAI’s fine tuning and classification. Currently, I think of looking how well a fine-tuned GPT-3 model can predict from the abstract of an article whether the automatic Stata repoduction is above some threshold like 90%. A high reproduction rate indicates that probably most data sets are available. Perhaps, from the topic described in the abstract, GPT-3 can already make a good guess about data availability.
Published on 08 Mar 2023 •